预备知识
线程与进程
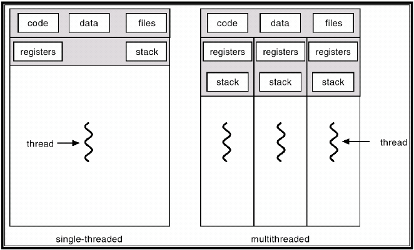
一个进程中是允许多个线程存在的,且进程与进程之间拥有完全独立的内存空间与数据。而同一进程内部的线程与线程中,虽都拥有独立的寄存器和栈空间,但他们可以共享代码,数据空间。也正因为这样的一个结构,使得线程之间的通信要比进程之间的通信要容易得多。
并发与并行
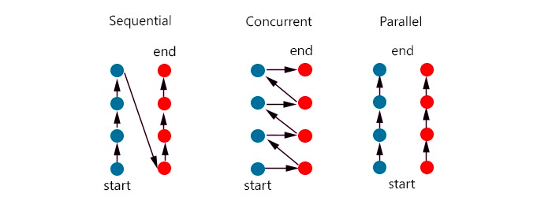
我们一般写的同步代码,就如同图中的Sequential(顺序执行),一个任务(蓝色圆圈为一个任务)完成了,才会继续运行另一个任务(红色圆圈)。而有时候为了提高效率也会用到并发,并行的机制。
图中的Concurrent即为并发机制,它是一下接收多个任务,但不要求任务必须要同一时间执行,而是可以执行部分任务A,然后转换到任务B执行一会儿,再跳回任务A如此往复,直至最终任务AB都完成。
并行就比较容易理解了,就是多个任务同一时间运行。常用的实现方式就是利用计算机多核,同时进行运算。
同步和异步
而在计算机概念中,我们经常听到同步和异步两个概念,这两个概念其实跟顺序执行和并发很相似. 同步,可以理解为在执行完一个函数或方法之后,一直等待系统返回值或消息,这时程序是出于阻塞的,只有接收到返回的值或消息后才往下执行其他的命令。异步,执行完函数或方法后,不必阻塞性地等待返回值或消息,只需要向系统委托一个异步过程,那么当系统接收到返回值或消息时,系统会自动触发委托的异步过程,从而完成一个完整的流程。
所以当需要执行I/O操作时,使用异步操作比使用线程+同步I/O操作更合适。I/O操作不仅包括了直接的文件、网络的读写,还包括数据库操作、Web Service、HttpRequest以及.Net Remoting等跨进程的调用。因为这些任务不需要CPU计算,只需要等待结果,在异步的情况下就能在非阻塞的情况下尽可能处理更多的操作。
Python GIL
在早期的Python版本中,Python用的Reference count机制来进行垃圾回收。即当一个地址的引用对象个数为0时,即可视作垃圾并进行内存回收。这种机制的好处是,容易实现且容易回收,但也带来了不少缺点。比如处理不了循环引用的情况,还有个缺点是在计算reference count的过程中需要锁住线程,不允许多线程操作。不然主线程算出来某个对象的引用计数可能是1,但与此同时另一个线程把计数变为了0,但是主线程没能回收该对象内存造成内存泄露。所以CPython编译器有个全局解释锁的概念,这样就能保证使用Reference count机制的时候能够保证只有一个线程进行。
GIL: 全局解释器锁(英语:Global Interpreter Lock,缩写GIL),是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。[1]即便在多核心处理器上,使用 GIL 的解释器也只允许同一时间执行一个线程。
多进程
由于GIL的存在,在Python环境中我们无法通过多线程的方式充分利用多核的性能。但是多进程是一个不错的替代方式,因为每个进程独自存在且使用各自独自的GIL。
协程
Python为了实现异步的机制,引入了协程Coroutine的概念。协程由于由程序主动控制切换,没有线程切换的开销,所以执行效率极高。对于IO密集型任务非常适用。在Python3.4之前,官方没有对协程的支持,存在一些三方库的实现,比如gevent和Tornado。3.4之后就内置了asyncio标准库,官方真正实现了协程这一特性。而Python对协程的支持,是通过Generator实现的,协程是遵循某些规则的生成器,关于生成器Generator的好处可以参考如下介绍https://www.programiz.com/python-programming/generator。
在Python3.5之前,协程的定义需要修饰器来装饰,但3.5之后则直接用async来代替, yield from则由await来代替。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import time
import asyncio
async def count():
print("One")
await asyncio.sleep(1)
print("Two")
async def main():
await asyncio.gather(count(), count(), count())
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"{__file__} executed in {elapsed:0.2f} seconds.")
该代码块运行结果如下,不难发现main函数是要运行三个协程任务,但当每个任务运行到asyncio.sleep的时候便立马切换到其他协程,然后当睡眠1s过后切换回来时,三个任务都依次完成。起到了异步的效果。其总时间只花了1s钟。
1
2
3
4
5
6
7
8
9
One
One
One
Two
Two
Two
./coroutine.py executed in 1.00 seconds.
Gevent也是一个出名的协程库,其用法与Asyncio完全不同,Gevent的宗旨是自动将标准库替换为协程库。如下例,虽然我们使用的是标准库的time.sleep(),但是gevent仍然能将其自动切换为协程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
from gevent import monkey
monkey.patch_all()
import gevent
import time
def eat():
print('eat food 1')
time.sleep(2)
print('eat food 2')
def play():
print('play 1')
time.sleep(1)
print('play 2')
g1=gevent.spawn(eat)
g2=gevent.spawn(play)
gevent.joinall([g1,g2])
print('end')
# print result
# eat food 1
# play 1
# play 2
# eat food 2
# end
patch_all函数则是可以设置需要替换的标准库,并最终达到异步的效果。
1
2
3
4
def patch_all(socket=True, dns=True, time=True, select=True, thread=True,os=True, ssl=True, subprocess=True, sys=False, aggressive=True, Event=True,
builtins=True, signal=True, queue=True, contextvars=True, **kwargs):
并发发送请求
需要注意的是,无论是否并发发送请求,使用session以及TCP连接池都是提升性能的必需选择。
Asyncio
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import asyncio
import requests
from aiohttp import ClientSession, TCPConnector
async def create_session():
"""Create session
"""
conn = TCPConnector(limit=100)
session = ClientSession(connector=conn)
return session
async def async_request(session, request_url, params):
"""Async route engine request"""
async with session.get(request_url, params=params) as response:
return await response.json(content_type=None)
async def gather_tasks(tasks):
"""Gather tasks"""
return await asyncio.gather(*tasks)
def send(batch_requests):
task_list = []
loop = asyncio.new_event_loop()
session = loop.run_until_complete(create_session())
for request in batch_requests:
task = async_request(session, request['request_url'], request['params'])
task_list.append(task)
# call route engine asynchronously
response = loop.run_until_complete(gather_tasks(task_list))
loop.run_until_complete(session.close())
loop.close()
return response
Asyncio + Multi-processing
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
import asyncio
import requests
from aiohttp import ClientSession, TCPConnector
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
async def create_session():
"""Create session
"""
conn = TCPConnector(limit=100)
session = ClientSession(connector=conn)
return session
async def async_request(session, request_url, params):
"""Async request"""
async with session.get(request_url, params=params) as response:
return await response.json(content_type=None)
def gather_tasks(batch):
"""Gather tasks"""
task_list = []
loop = asyncio.new_event_loop()
session = None
try:
asyncio.set_event_loop(loop)
session = loop.run_until_complete(create_session())
for request in batch:
task = async_request(session, request['request_url'], request['params'])
task_list.append(task)
# Send requests asynchronously
return loop.run_until_complete(asyncio.gather(*task_list))
finally:
loop.run_until_complete(session.close())
loop.close()
async def join(request_batch, PAGE_SIZE=1000):
"""Gather tasks"""
loop = asyncio.get_event_loop()
executor = ProcessPoolExecutor(max_workers=10)
futures = []
for i in range(0, len(request_batch), PAGE_SIZE):
future = loop.run_in_executor(executor, gather_tasks, request_batch[i:i+PAGE_SIZE])
futures.append(future)
return await asyncio.gather(*futures)
def send(batch_requests):
task_list = []
loop = asyncio.new_event_loop()
response = loop.run_until_complete(join(batch_requests))
loop.close()
return response
Gevent + Pool
尽管我们使用的是requests同步库,但是patch_socket可以自动将socket切换为异步协程grequests库。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import time
import requests
import gevent
import gevent.monkey
gevent.monkey.patch_socket()
session = requests.Session()
adapter = requests.adapters.HTTPAdapter(pool_connections=10, pool_maxsize=10)
session.mount('http://', adapter)
for j,d in enumerate(data):
tasks = []
for i in d:
g = gevent.spawn(session.post, i['request_url'], json=i['params'])
tasks.append(g)
start = time.time()
gevent.joinall(tasks)
end = time.time()
print('{}th, request_num: {}, time_cost: {}'.format(j, len(data[j]), end-start))
session.close()
参考
廖雪峰
https://juejin.im/post/5c13245ee51d455fa5451f33
Python并行编程
https://ashooter.github.io/2018-11-19/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3Python%E7%9A%84asyncio%E5%8D%8F%E7%A8%8B/
https://github.com/AndreLouisCaron/a-tale-of-event-loops