算法
相比RNN只有一个传递状态$h^t$,LSTM有两个传输状态,一个$C^t$(cell state),和一个$h^t$(hidden state)。RNN中的$h^t$对于LSTM中的$C^t$)
其中对于传递下去的$C^t$改变得很慢,通常输出的$C^t$是上一个状态传过来的$C^{t-1}$加上一些数值,这也是LSTM相比RNN为什么能缓解梯度消失和梯度爆炸的原因。而$h^t$则在不同节点下往往会有很大的区别。
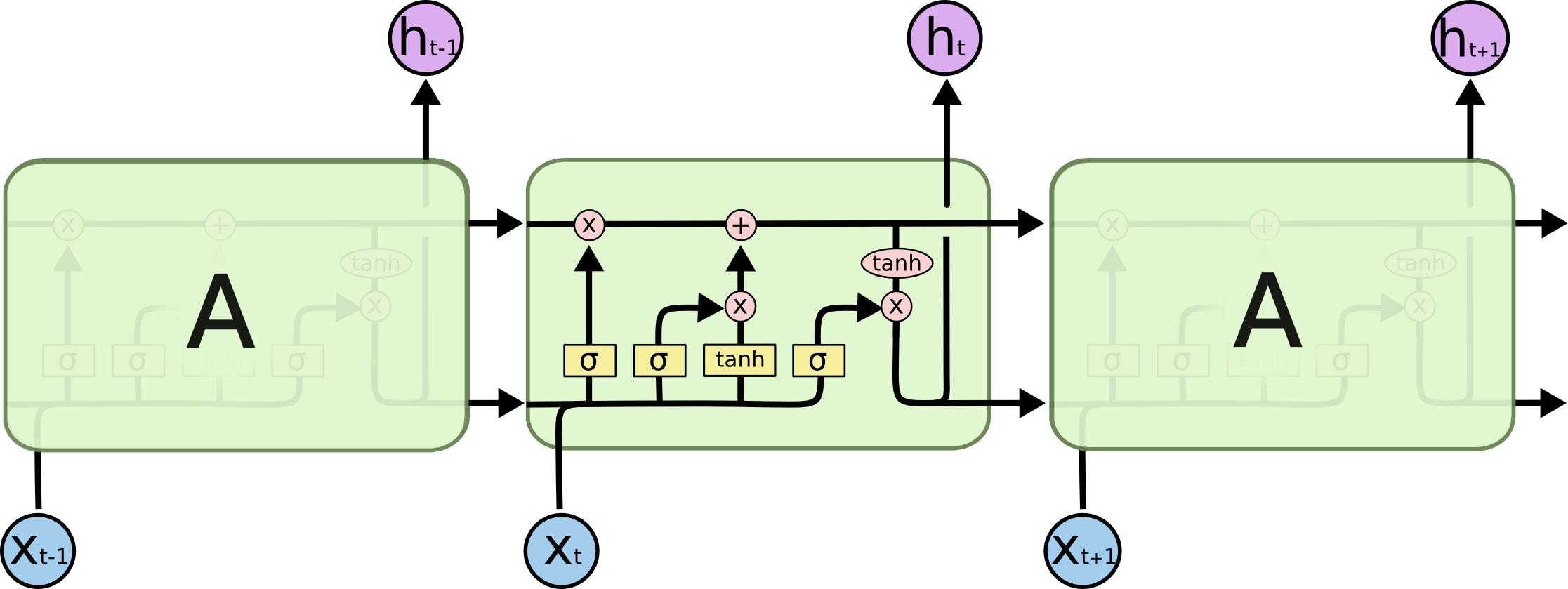
更新cell state的公式如下,细胞状态$𝐶^𝑡$由两部分组成,第一部分是$𝐶^{𝑡−1}$和遗忘门输出$𝑓^𝑡$的乘积,第二部分是输入门的$𝑖^𝑡$和$𝑎^𝑡$的乘积。 $$ C^{(t)} = C^{(t-1)} \odot f^{(t)} + i^{(t)} \odot a^{(t)} $$
输入门两部分组成$𝑖^𝑡$和$𝑎^𝑡$公式如下,其中$𝑖^𝑡$的激活函数为sigmoid函数,$𝑎^𝑡$为tanh函数。遗忘门部分$f^{(t)}$如下,其中𝑊,𝑈,𝑏为线性关系的系数和偏倚。 $$ i^{(t)} = \sigma(W_ih^{(t-1)} + U_ix^{(t)} + b_i) $$
$$ a^{(t)} =tanh(W_ah^{(t-1)} + U_ax^{(t)} + b_a) $$
$$ f^{(t)} = \sigma(W_fh^{(t-1)} + U_fx^{(t)} + b_f) $$
输出门公式如下,可以看出隐状态$h^{(t)}$是细胞状态$C^{(t)}$的函数 $$ o^{(t)} = \sigma(W_oh^{(t-1)} + U_ox^{(t)} + b_o) $$
$$ h^{(t)} = o^{(t)} \odot tanh(C^{(t)}) $$
代码
关于该示例的源码可从如下github链接下载, https://github.com/xcTorres/machine_learning/blob/master/lstm.ipynb。
读取数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import numpy as np
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
df = pd.read_csv('./data/ner_dataset.csv', encoding = "ISO-8859-1")
df = df.fillna(method='ffill')
df.head()
class SentenceGetter(object):
def __init__(self, data):
self.n_sent = 1
self.data = data
self.empty = False
agg_func = lambda s: (s['Word'].values.tolist(), s['Tag'].values.tolist())
self.grouped = self.data.groupby('Sentence #').apply(agg_func)
self.sentences = [s for s in self.grouped]
def get_next(self):
try:
s = self.grouped['Sentence: {}'.format(self.n_sent)]
self.n_sent += 1
return s
except:
return None
getter = SentenceGetter(df)
词转索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def prepare_sequence(seq, to_ix):
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
word_to_ix = {}
tag_to_ix = {}
# For each words-list (sentence) and tags-list in each tuple of training_data
for sent, tags in getter.sentences:
for word in sent:
if word not in word_to_ix: # word has not been assigned an index yet
word_to_ix[word] = len(word_to_ix) # Assign each word with a unique index
for tag in tags:
if tag not in tag_to_ix:
tag_to_ix[tag] = len(tag_to_ix)
print(tag_to_ix)
定义LSTM结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
EMBEDDING_DIM = 32
HIDDEN_DIM = 32
class LSTMTagger(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size):
super(LSTMTagger, self).__init__()
self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
# The LSTM takes word embeddings as inputs, and outputs hidden states
# with dimensionality hidden_dim.
self.lstm = nn.LSTM(embedding_dim, hidden_dim)
# The linear layer that maps from hidden state space to tag space
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
lstm_out, _ = self.lstm(embeds.view(len(sentence), 1, -1))
tag_space = self.hidden2tag(lstm_out.view(len(sentence), -1))
tag_scores = F.log_softmax(tag_space, dim=1)
return tag_scores
训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from sklearn.model_selection import train_test_split
X = [s[0] for s in getter.sentences]
y = [s[1] for s in getter.sentences]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
model = LSTMTagger(EMBEDDING_DIM, HIDDEN_DIM, len(word_to_ix), len(tag_to_ix))
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
for epoch in range(20):
print(epoch)
for sentence, tags in zip(X_train, y_train):
# Step 1. Remember that Pytorch accumulates gradients.
# We need to clear them out before each instance
model.zero_grad()
# Step 2. Get our inputs ready for the network, that is, turn them into
# Tensors of word indices.
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = prepare_sequence(tags, tag_to_ix)
# Step 3. Run our forward pass.
tag_scores = model(sentence_in)
# Step 4. Compute the loss, gradients, and update the parameters by
# calling optimizer.step()
loss = loss_function(tag_scores, targets)
loss.backward()
optimizer.step()
预测
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import numpy as np
label_pred = np.array([])
with torch.no_grad():
for t in X_test:
inputs = prepare_sequence(t, word_to_ix)
tag_score = model(inputs)
label_pred = np.append(label_pred, torch.argmax(tag_score, dim=1).numpy())
y = []
for i in y_test:
for w in i:
y.append(tag_to_ix[w])
from sklearn.metrics import f1_score
f1_score(label_pred, y, average='weighted')
Reference
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://www.cnblogs.com/pinard/p/6519110.html
RNN反向传播推导
https://zhuanlan.zhihu.com/p/104475016
https://zhuanlan.zhihu.com/p/32085405